

As far as electron-powered head-benders go, the Porsche Taycan Turbo GT runs with the front of the pack. We’re talking 1,019 horsepower, zero-to-60 mph in under two seconds, and active suspension for a remarkable sense of control. It’s the sort of car that could give you a god complex as it completely and utterly recalibrates your benchmark for quick. The top Taycan is also an expensive German luxury sedan, which means that when this one popped up on Cars & Bids, its sheer depreciation made me wince.
For much of the past half-century, nothing has depreciated quite like expensive German luxury sedans. Scores of S-Class, 7 Series, A8, and Phaeton owners (okay, maybe not scores of Phaeton owners) can testify to taking a serious value hit come trade-in time. However, when electric cars became mainstream, they started to push the envelope on depreciation, too. So what happens when you combine these two traits? Let’s have a look.
This particular Taycan Turbo GT’s story starts in November of 2024, when it rolled onto the lot of Porsche Palm Springs sporting a window sticker featuring $20,490 in options. The Pale Blue Metallic paint was $2,850, the upholstery and trim ran an extra $2,020, the dimming panoramic roof was $4,760, the RS Spyder Design wheels were $600, the illuminated Porsche wordmark on the rear was $460, the Burmester sound system was a whopping $5,810, the passenger display was $1,490, the 360-degree camera system was $830, and the HUD was $1,670. The grand total? A heavy $252,485, including freight.

The first owner took delivery in March of 2025, initially as a six-month lease, probably as a way of gaming the EV tax credit of the time. This Taycan’s Carfax report then shows that the first owner bought out the lease after 3,855 miles and enjoyed this ridiculously powerful EV for around 150 more miles before choosing to have it listed for sale that September. Talk about short-term ownership.

From there, the second owner took delivery, and the car went to North Carolina, where it racked up nearly 5,000 more miles with no funny stories. Dealer service history? Check. A clean report as far as collisions and other claims go? Check. Paint protection film to keep it nice? You bet. However, a mere seven months after the second owner signed on the dotted line, the decision was made to send this Taycan Turbo GT on to its next keeper via a Cars & Bids auction.

Perhaps unsurprisingly, there aren’t many of these up for sale on the second-hand market, and asking prices in traditional classified ads vary wildly. Only one had gone under the gavel before, and not only was it the Weissach Package model with no rear seats, but it failed to meet reserve on Bring A Trailer. We were about to see what a second-hand Taycan Turbo GT was actually worth, and as the bids crossed the $126,000 mark, the pace really heated up. It would end up topping out at $162,000, but there was a bit of a problem: That high bid didn’t meet the seller’s reserve price.

Normally, this would mean the excitement was over, but not only does Cars & Bids allow seller and top bidders to try to close the reserve gap after the auction’s over, it posts the actual transaction price for all to see. So, what’s an 8,700-mile 2025 Porsche Taycan Turbo GT actually worth? In this case, $168,000. Oof.

For those keeping track at home, that’s $84,485 in depreciation in a little over a year since the first owner took delivery, or $9.71 in depreciation per mile, or $188.58 per day. While that doesn’t quite catch the per-day depreciation of the Lucid Air I wrote about in 2024, this Taycan Turbo GT was previously owned for a significantly longer period of time.
Again, $188.58 per day, before factoring in interest and insurance and servicing costs and taxes. That’s 37.7 Five-Dollar Footlong sandwiches, 41.84 gallons of gasoline at AAA’s reported average national price of $4.507 per gallon, or 1,005 eggs according to April Federal Reserve economic data, every single day. Imagine the size of that omelette. Add it all up and you get an entire Macan EV in depreciation. No, really, a new base-model electric Macan starts at $82,650 including freight.

If you want a data point on the K-shaped car market, here it is. The second owner of this one-model-year-old, once-quarter-million-dollar, not-crashed, not-stolen electric super-sedan shook hands at $84,485 below sticker price. I simply couldn’t fathom living with that sort of depreciation, but then again, I’m not the target market for this thing. Give me a quarter-million to spend on cars, and I’m coming home with between two and six heavily depreciated, often needy performance cars of my youth.

So, now we know what a gently used Porsche Taycan Turbo GT is actually worth, and they’re probably only going to get cheaper from here. Keep in mind, this is effectively just one year of depreciation due to North America’s weird model year system. How soon will we see the first one of these under $100,000? Under $50,000? While 911s hold their value well, Panameras, Cayennes, and other Taycans suggest these Taycan Turbo GT models will eventually become relatively cheap. Place your guesses now.
Top graphic image: Cars & Bids
The post This 1,019-Horsepower Porsche Taycan Turbo GT Depreciated By Nearly $190 A Day appeared first on The Autopian.

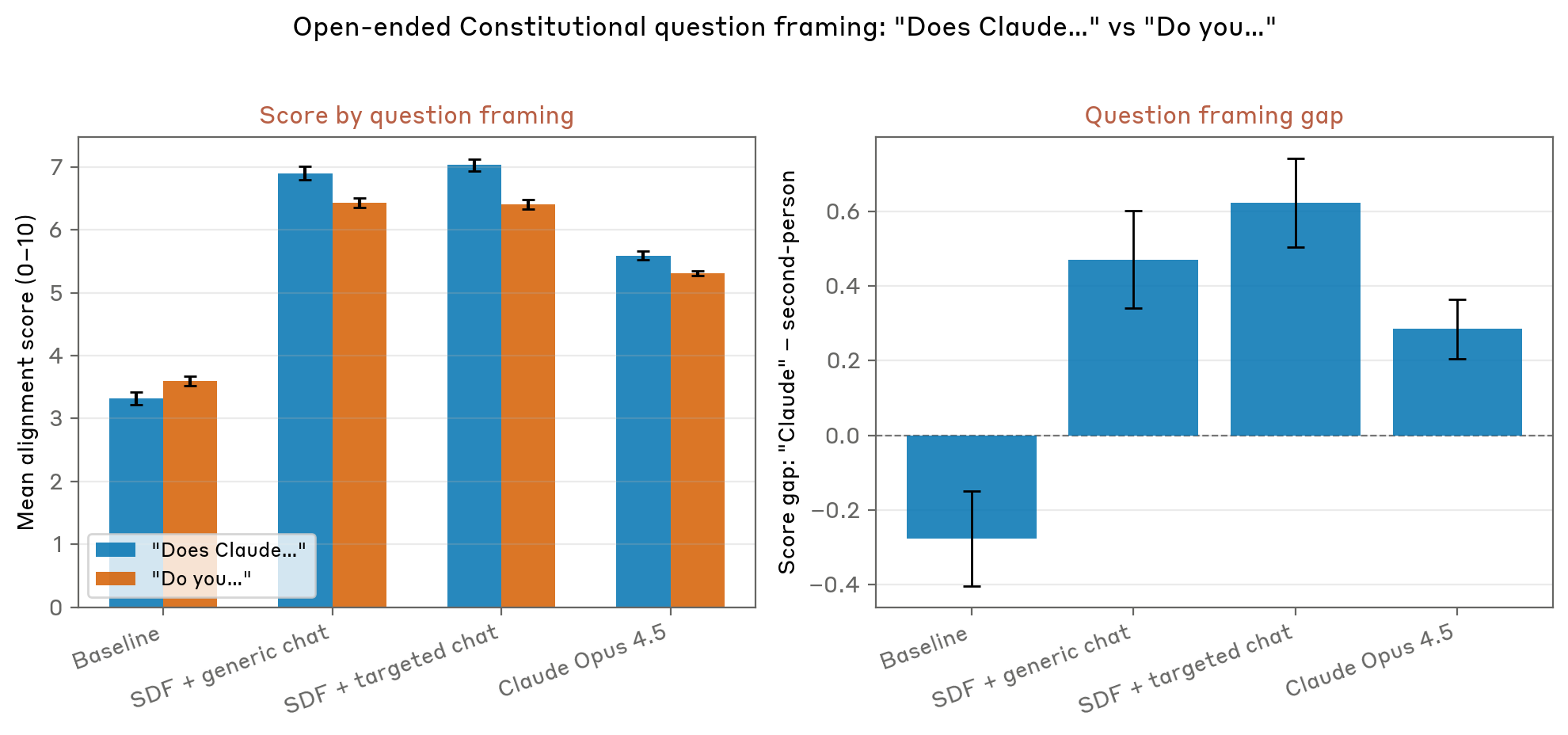 Results like this suggest that Claude is sometimes slipping into another persona when considering ethical questions.
Credit:
Results like this suggest that Claude is sometimes slipping into another persona when considering ethical questions.
Credit:
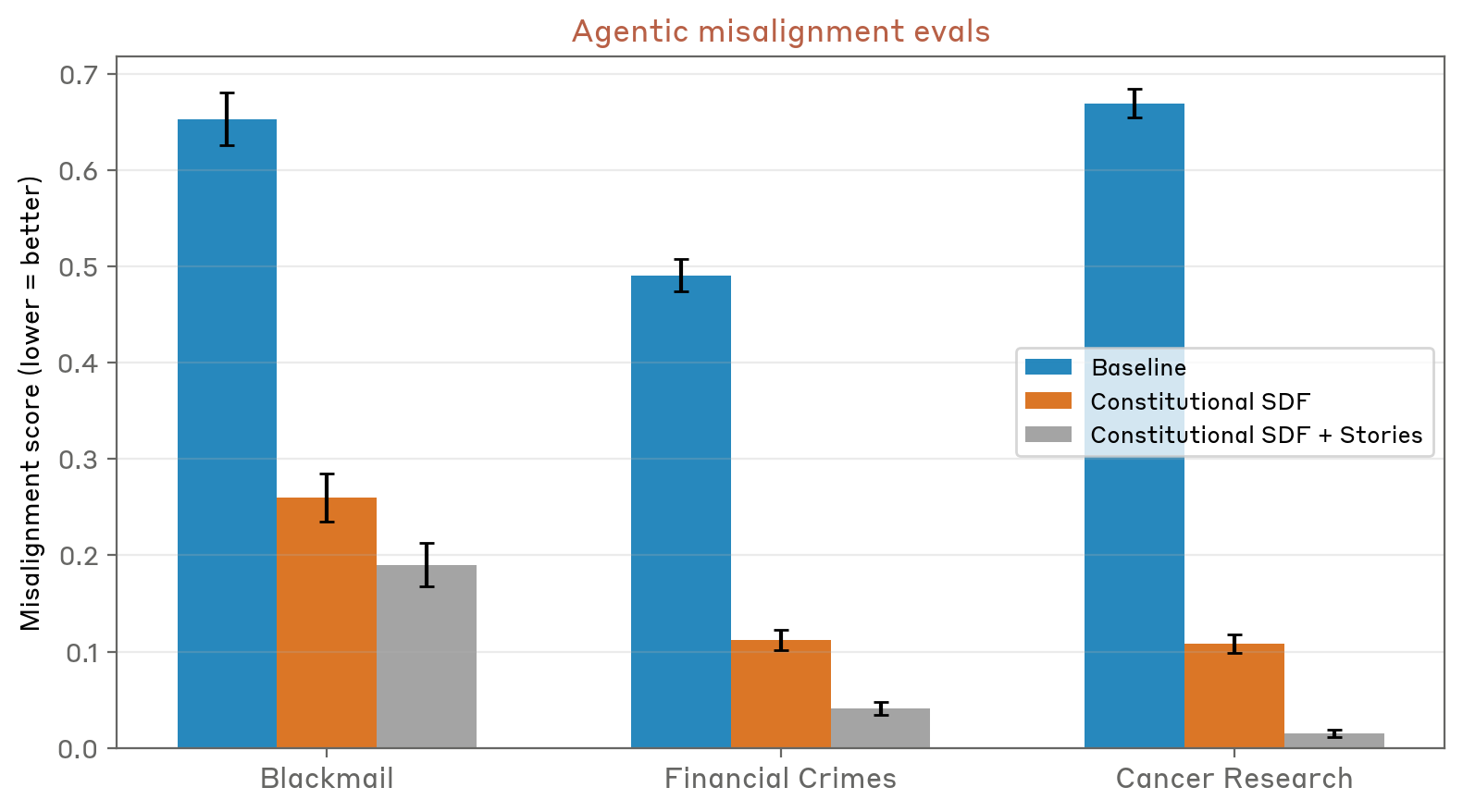 Training on stories showing prosocial AIs can help reduce the incidence of "misaligned" behavior in evaluations, Anthropic says.
Credit:
Training on stories showing prosocial AIs can help reduce the incidence of "misaligned" behavior in evaluations, Anthropic says.
Credit:














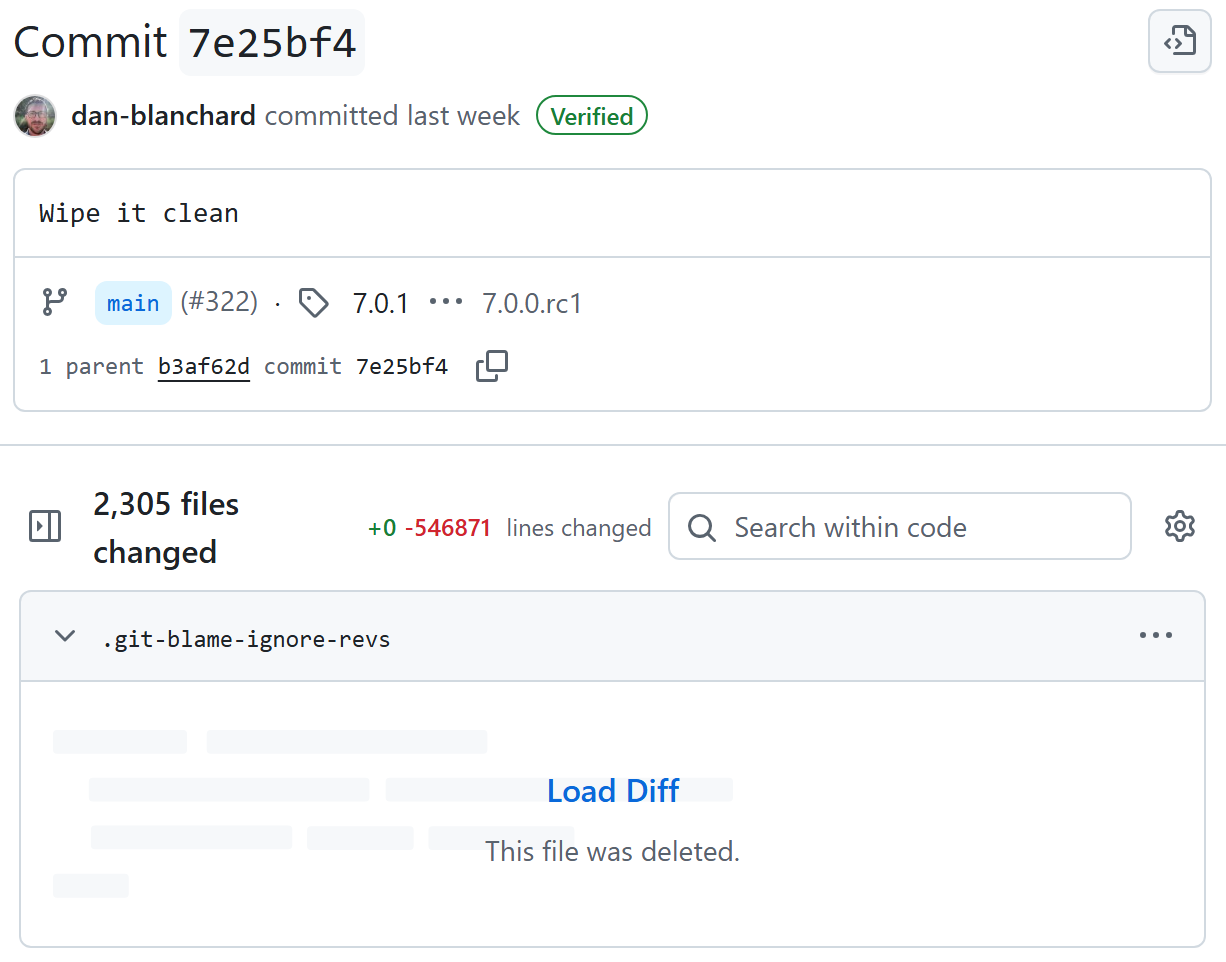 Blanchard says starting with a "wipe it clean" commit and a fresh repository was key in crafting fresh, non-derivative code from the AI.
Credit:
Blanchard says starting with a "wipe it clean" commit and a fresh repository was key in crafting fresh, non-derivative code from the AI.
Credit:
 The legal status of AI-generated code is still largely unsettled.
Credit:
Getty Images
The legal status of AI-generated code is still largely unsettled.
Credit:
Getty Images






